op = Function("op", IntSort(), IntSort(), IntSort()) solver = Solver()
for left inrange(order): for right inrange(order): solver.add(op(left, right) >= 0, op(left, right) < order)
for element inrange(order): solver.add(op(0, element) == element) solver.add(op(element, 0) == element) solver.add(Distinct([op(element, other) for other inrange(order)])) solver.add(Distinct([op(other, element) for other inrange(order)]))
for row inrange(1, order): for col inrange(1, order): clue = grid[row][col] if clue isnotNone: solver.add(op(row, col) == clue)
for a inrange(order): for b inrange(order): for c inrange(order): solver.add(op(a, op(b, c)) == op(op(a, b), c))
lemma complement_divmod_10 {a b k : ℕ} : a + b = 10 ^ (k + 1) - 1 ↔ a / 10 + b / 10 = 10 ^ k - 1 ∧ a % 10 + b % 10 = 9 := by constructor · intro h have h2: (a % 10 + b % 10) % 10 = 9 := by rw [← Nat.add_mod, h] induction k with | zero => simp | succ k ih => rw [Nat.pow_succ, Nat.mod_eq_sub_iff (c := 1) (by decide) (by decide)] rw [← Nat.pow_succ, Nat.sub_add_cancel (Nat.one_le_pow _ _ (by decide))] apply Nat.dvd_mul_left omega · rintro ⟨ha, hb⟩ rw [← Nat.div_add_mod' a 10, ← Nat.div_add_mod' b 10] have : (a / 10 * 10 + a % 10) + (b / 10 * 10 + b % 10) = (a / 10 + b / 10) * 10 + (a % 10 + b % 10) := by ring rw [this, ha, hb] rw [Nat.sub_mul, ← Nat.pow_succ] have : 10 ≤ 10 ^ (k + 1) := by apply Nat.le_pow; simp rw [← Nat.sub_add_comm this, Nat.add_sub_add_right]
lemma digitSum_eq_9k_of_complement {a b k : ℕ} (h : a + b = 10 ^ k - 1) : digitSum a + digitSum b = 9 * k := by induction k generalizing a b with | zero => norm_num at *; simp [digitSum, h] | succ k ih => rw [complement_divmod_10] at h rw [digitSum_divmod_10 a, digitSum_divmod_10 b] rw [mul_add_one, ← ih (h.left), ← h.right] ac_rfl
-- For all natural number n, k such that 1 ≤ n ≤ 10^k, show that the digit sum of (10^k - 1)n is 9k. example (k : ℕ) (n : ℕ) (hn : 1 ≤ n ∧ n <= 10 ^ k) : digitSum ((10 ^ k - 1) * n) = 9 * k := by -- (10^k - 1) * n = 10^k * n - n = (n - 1) * 10^k + (10^k - n) -- divide the digits into two parts: -- 1. digitSum ((n - 1) * 10^k) = digitSum (n - 1) -- 2. digitSum (10^k - n) = digitSum ((10^k - 1) - (n - 1)) = 9 * k - digitSum (n - 1) let x := (10^k - 1) * n have hSplit : x / 10^k = n - 1 ∧ x % 10^k = 10^k - n := by rw [Nat.div_mod_unique (Nat.pow_pos (by decide))] constructor · dsimp [x] zify [hn.left, hn.right, show 1 ≤ 10^k from Nat.one_le_pow _ _ (by decide)] ring · exact Nat.sub_lt (Nat.pow_pos (by decide)) hn.left rw [digitSum_divmod_power_of_10 _ k, hSplit.left, hSplit.right] apply digitSum_eq_9k_of_complement rw [← Nat.sub_add_comm hn.left, Nat.add_sub_of_le hn.right]
处理复杂功能时表现不佳:我本来想让 Claude Code 实现一个 drag & drop,但它死活写不对,只好先放弃了。
瑕不掩瑜,强烈建议需要大量写代码(尤其是前后端、CLI等典型场景)的人试一试 Claude Code。Claude Pro $20/mo 的订阅价格和它的功能相比非常划算。目前 Claude Pro 提供的额度还是很慷慨的,大概能支撑你每 5h 高强度使用(上一条恢复后立刻开始下一条)2h。低强度使用的话根本不需要担心额度问题。
小技巧
以下是我使用 Claude Code 的过程中摸索出来的一些小技巧。
通知
Claude Code 执行一个任务可能需要几分钟,这段时间一直盯着终端有点浪费时间。可以加个 hook,让它在请求权限或任务完成时发送通知。把以下内容写到 ~/.claude/settings.json 中即可。(非 Linux 系统请自行修改命令)
These specific phrases are mapped directly to increasing levels of thinking budget in the system: "think" < "think hard" < "think harder" < "ultrathink." Each level allocates progressively more thinking budget for Claude to use.
在实现复杂功能之前,开启 plan mode 并加入 ultrathink 关键词可以让 Claude Code 先思考出一个详细的计划。
中途输入
你可以在任何时刻向 Claude Code 提供输入,它会在完成下一次工具交互后读入这些内容。比如你发现它犯错后,你可以及时纠正,而不需停止整个任务。
继续对话
claude --resume 可以选择一个之前的对话继续进行。claude --continue 会继续最近的对话。
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model model_name = "Qwen/Qwen2.5-0.5B-Instruct" model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto") tokenizer = AutoTokenizer.from_pretrained(model_name)
# Create test input message = "You are a are not a" message_tokenized = tokenizer.encode(message, return_tensors="pt").to(model.device) assert message_tokenized.shape[-1] == 6
(* take first n elements from list xs *) let take n xs = letrec take_impl acc n xs = match (n, xs) with | (0, _) -> acc | (_, []) -> acc | (n, x::xs) -> take_impl (x::acc) (n-1) xs inList.rev (take_impl [] n xs)
(* drop first n elements from list xs *) letrec drop n xs = match (n, xs) with | (_, []) -> [] | (0, xs) -> xs | (n, _::xs) -> drop (n-1) xs
Copied from lipsum.com
1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Mermaid 图
sequenceDiagram
Alice->>John: Hello John, how are you?
John-->>Alice: Great!
Alice-)John: See you later!
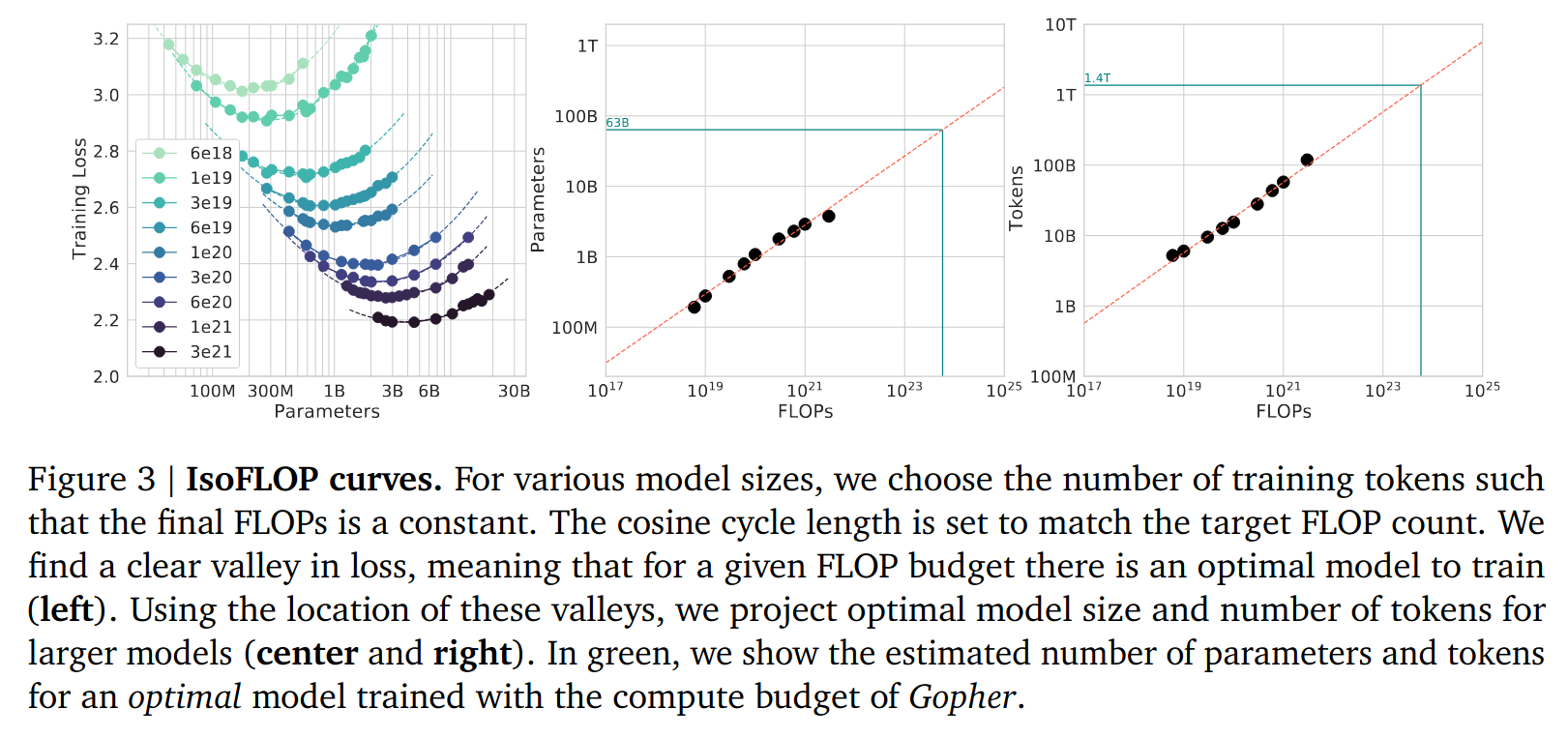
给定总计算量(这直接由预算决定),Llama 团队希望训练出一个尽可能强的模型。盲目增加参数量并不是最优解:增加参数意味着减少训练数据量,而一个欠拟合的大模型未必比一个充分拟合的较小模型更优。DeepMind 团队在 2022 年研究了该问题。这篇文章在固定总计算量的条件下训练了大量不同尺寸的 LLM,并观察到(最小化 loss 意义下的)最优模型尺寸与总计算量之间存在与数据相当吻合的经验关系。Llama 3 沿用了这一方法,但重做了其中的实验。实验得出的数据与原文有差异,但结论是一致的。405B 的选择正是根据这项数据外推得来。图片出自 Training Compute-Optimal Large Language Models
作者曾经读到过一句话:“工程师是能用最低限度的创新达成目的的人。”Llama 3 正是这样:其成功的最主要原因并非其方法论所含的原创性,而是大量人力、算力资源的投入以及对现有 best practice 的有效整合。这样的工作是否预示着在不久的将来,深度学习领域“单打独斗”的时代将会迎来结束?这是一个引人遐想的问题。
用于监控训练进程的指标是原长度下的表现和新长度下 needle in a haystack 测试的成功率。当模型 100% 完成 needle in a haystack 任务,且在原长度下的表现恢复到训练前水平时,即认为模型适应了新的上下文长度,接下来再进行下一轮上下文增长,直到达到最终的 128K。