LLM 学习笔记(一):Transformer 模型的三种架构
Transformer 模型通常采用三种主要架构:encoder-decoder、encoder-only 和 decoder-only。
1.1 Encoder-decoder
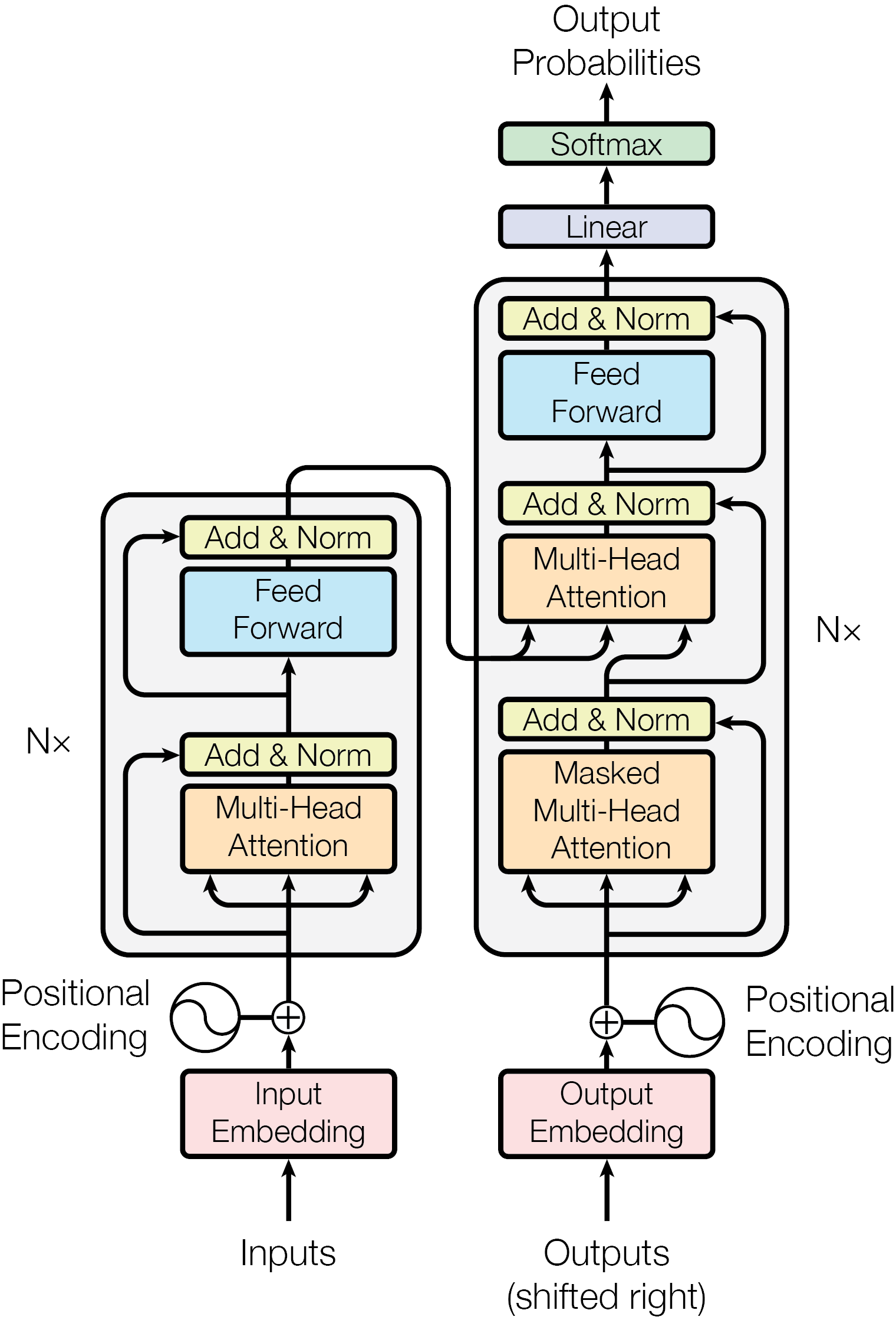
Transformer 原始论文中设计的模型架构就是 encoder-decoder 的。Encoder 通过双向自注意力处理输入,decoder 通过单向自注意力逐个生成输出,encoder 通过互注意力向 decoder 传递信息。
Encoder-decoder 架构起源于机器翻译等输入和输出之间具有一定异质性的任务。对于这种任务,使用一个模型理解输入,另一个模型生成输出是合理的做法。然而,在 LLM 的主要任务(QA、续写、聊天等)中,输入和输出是高度同质的(它们大概率是同一种语言,且在逻辑上相承接),这时使用两个模型分别处理两部分信息不仅没有必要,还会在模型设计中引入额外的复杂性。因此,LLM 架构中 decoder-only 的占比远远高于 encoder-decoder。
1.2 Encoder-only
这类模型的典型代表为 BERT。这一模型是文本理解领域的经典 backbone。
BERT 的预训练是自监督的,包括两个任务。
较为重要的一个是预测被 mask 的 token,一种类似于 denoising autoencoder 的经典预训练方法。具体而言,输入中随机 15% 的 token 会被 mask 掉(80% 概率变为 [MASK],10% 概率变为随机 token,10% 概率不变),而模型的任务就是还原这些 token。通过这个任务,模型可以学到 token 与 token 之间的双向关系,这是 next token prediction 做不到的。
另一个任务是 next sentence prediction,即输入两个语段,预测它们是否出自同一篇文章的相邻片段。这个任务可以加强模型对语段之间关系的理解。
BERT 可以生成用于下游文本理解任务的 deep representation,但不适合用于文本生成。虽然确实存在这样的方法,但其生成过程明显比 decoder-only 模型更复杂。究其原因,BERT 被训练为利用双向信息理解语言,但生成文本的过程本质上是单向的(生成文本时,模型只知道已经生成的 token,但不知道未来的 token)。这导致朴素的生成方式用于 BERT 时效果很差。
1.3 Decoder-only
目前的绝大多数 LLM 都是 decoder-only 语言模型。这类语言模型主要由四部分组成:
- Tokenizer:tokenizer 负责在输入文本和 token 序列之间相互转换。token 是语言模型处理信息的最小单位。对于英语输入,token 通常是一个完整单词或较不常用单词的一部分(在 ChatGPT 的 tokenizer 中,一个 token 大概相当于 3/4 个英文单词)。可能的 token 总数大致为 \(10^5\) 量级。
- Embedding:embedding 层是一个可学习的表,将每个 token 映射到一个高维向量。经过 tokenizer 和 embedding 层之后,文本输入被转化为一个 \(\mathrm{num\_tokens} \times \mathrm{embed\_dim}\) 的矩阵。
- Transformer 网络: 这一部分包含了模型的绝大部分计算量。每个 transformer 块包含一个掩蔽多头自注意力层和一个 feed-forward network(通常是两层神经网络),配有归一化和残差连接。在 LLM 中,整个网络通常由连续数十个规模相同的 transformer 块组成。
- LM head:这是模型的输出层,将 transformer 网络的输出转化为下一个 token 的概率分布。推理时,LM head 的输出通过一些采样方法生成出 token 序列,再通过 tokenizer 转换为文本。
以下是 Meta-Llama-3.1-8B-Instruct 和 Qwen2.5-7B-Instruct 的大致架构,可以发现两者大同小异:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 4096, padding_idx=128004)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=128256, bias=False)
)
Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(152064, 3584)
(layers): ModuleList(
(0-27): 28 x Qwen2DecoderLayer(
(self_attn): Qwen2SdpaAttention(
(q_proj): Linear(in_features=3584, out_features=3584, bias=True)
(k_proj): Linear(in_features=3584, out_features=512, bias=True)
(v_proj): Linear(in_features=3584, out_features=512, bias=True)
(o_proj): Linear(in_features=3584, out_features=3584, bias=False)
(rotary_emb): Qwen2RotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=3584, out_features=18944, bias=False)
(up_proj): Linear(in_features=3584, out_features=18944, bias=False)
(down_proj): Linear(in_features=18944, out_features=3584, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((3584,), eps=1e-06)
)
(lm_head): Linear(in_features=3584, out_features=152064, bias=False)
)
Decoder-only 语言模型的预训练任务为 next token prediction。具体而言,模型对每个位置预测其 token 种类的概率分布(由于 transformer decoder 使用的是掩蔽自注意力,模型预测某个位置时只能看到它之前的 token),训练目标为最大化正确文本的 log likelihood。推理与其他模型类似,逐个采样即可。
在 decoder-only 语言模型的发展过程中,积累的量变产生了质变。这一点由 GPT 系列的发展可见一斑: