LLM 学习笔记(二):从头训练 LLM 的简要流程
本章以 Llama 3 为讨论对象。
2.1 模型设计
Llama 3 的模型架构较为常规,但值得一提的是其模型尺寸的选择。Llama 3 的旗舰版本是 405B 而非常见的 70B,这一选择是经过了充分分析和论证的。
给定总计算量(这直接由预算决定),Llama 团队希望训练出一个尽可能强的模型。盲目增加参数量并不是最优解:增加参数意味着减少训练数据量,而一个欠拟合的大模型未必比一个充分拟合的较小模型更优。DeepMind 团队在 2022 年研究了该问题。这篇文章在固定总计算量的条件下训练了大量不同尺寸的 LLM,并观察到(最小化 loss 意义下的)最优模型尺寸与总计算量之间存在与数据相当吻合的经验关系。Llama 3 沿用了这一方法,但重做了其中的实验。实验得出的数据与原文有差异,但结论是一致的。405B 的选择正是根据这项数据外推得来。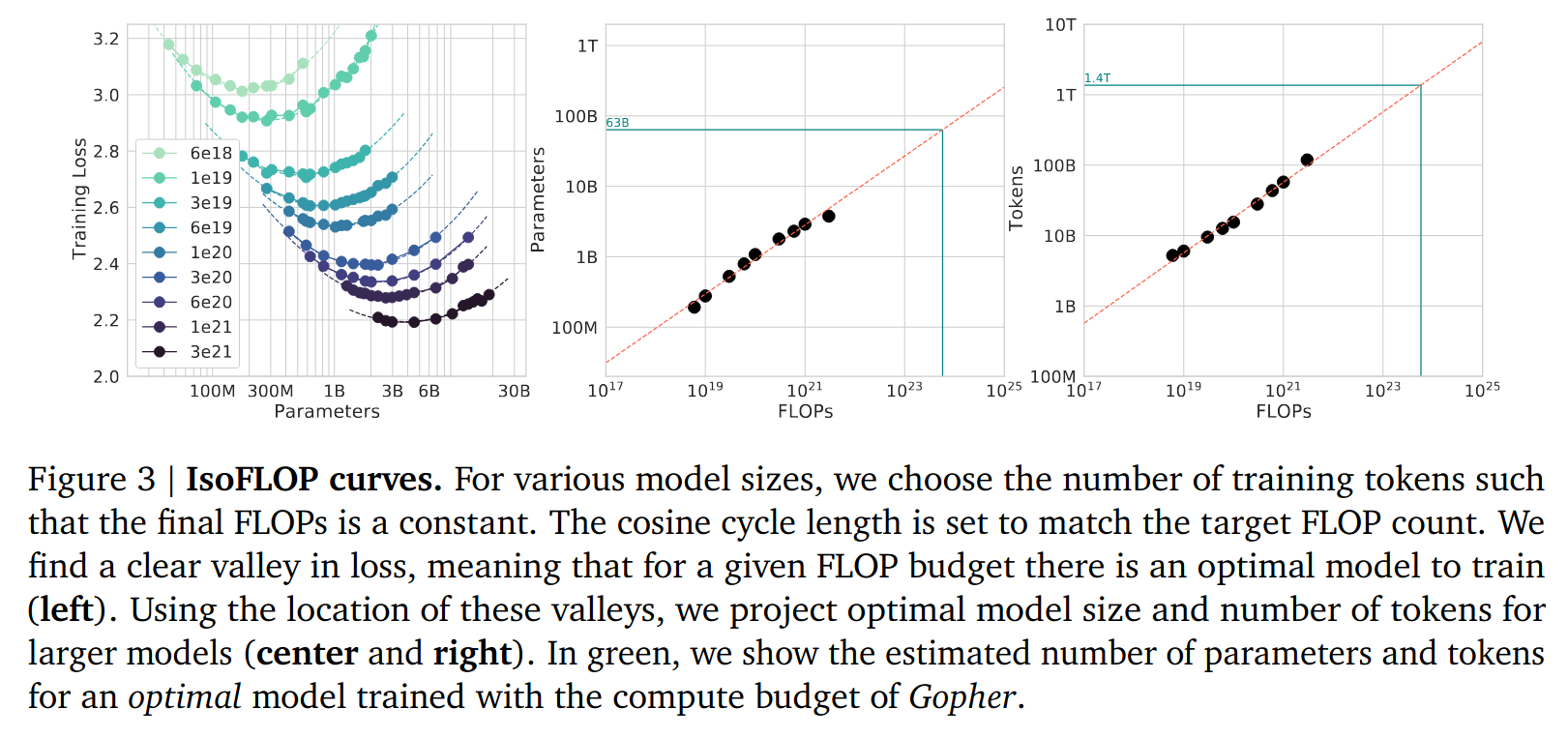
作者曾经读到过一句话:“工程师是能用最低限度的创新达成目的的人。”Llama 3 正是这样:其成功的最主要原因并非其方法论所含的原创性,而是大量人力、算力资源的投入以及对现有 best practice 的有效整合。这样的工作是否预示着在不久的将来,深度学习领域“单打独斗”的时代将会迎来结束?这是一个引人遐想的问题。
2.2 Pre-training
Llama 3 的预训练分为三个步骤:初始训练、上下文增长和 annealing(冷却?)。
2.2.1 初始训练
训练由一个较短的预热阶段(学习率线性增长)和一个较长的主阶段(学习率余弦衰减)组成。模型初始阶段很不稳定,因此使用更低的学习率和更小的 batch size 以保证梯度在合理范围内,使模型的学习更加可控。
值得一提的是,训练数据不仅在内容上进行了多方面的把控,不同类型数据的配比也是刻意调整优化过的。得益于 scaling law,小模型上的实验结果可以较为可靠地迁移到大模型上,使得对训练数据配比的调优成为可能。展现了深度学习中炼金术的一面
2.2.2 上下文增长
由于 transformer 模型的算力消耗随输入长度是超线性增长的,以超长上下文训练会拖慢训练效率。因此,模型在初始训练阶段以 8K 上下文长度进行训练,训练好之后逐步增长到 128K。
用于监控训练进程的指标是原长度下的表现和新长度下 needle in a haystack 测试的成功率。当模型 100% 完成 needle in a haystack 任务,且在原长度下的表现恢复到训练前水平时,即认为模型适应了新的上下文长度,接下来再进行下一轮上下文增长,直到达到最终的 128K。
2.2.3 冷却
在以上两个阶段后,还会再进行一个较短的冷却阶段(学习率线性衰减)。这一阶段使用精选的高质量数据进行训练。这或许是 LLM 版的“考前冲刺”?
2.3 Post-training
经过 pre-training 后,模型具有了理解语言的能力,但它只学习了文本续写这一项任务。想要让模型顺利地和人类对话,还需要作出一定微调。
2.3.1 Instruction Tuning
首先,需要规定一种用于对话的格式,以便 LLM 知道上文的每一部分都来自于谁(系统/用户/LLM/工具...)。以 Llama 3.1 为例,一个简单的 prompt 如下:(形如 <|begin_of_text|> 的为特殊 token)1
2
3
4
5
6
7
8<|begin_of_text|><|start_header_id|>system<|end_header_id|>
Cutting Knowledge Date: December 2023
Today Date: 23 July 2024
You are a helpful assistant<|eot_id|><|start_header_id|>user<|end_header_id|>
What is the capital of France?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
定义了对话格式后,需要在对话数据上微调 LLM。对话数据可能来自于人,也可能由已经 post-training 过的 LLM 生成。
2.3.2 偏好学习
仅仅在格式上让 LLM 适配对话是不够的。互联网上存在大量的低质量内容,也包含很多我们不希望 LLM 去模仿的行为(如恶意言论)。因此,需要让 LLM 学习在人类看来更加“正确”的行为,而非无意识地模仿互联网上的内容。
构建高质量的对话数据集是较为困难的。但是还有一种相对容易的获取人类偏好的方式:让人类比较对同一问题的两个回答孰优孰劣。模型通过某种方式的学习,提高生成较优答案的概率,降低生成较劣答案的概率,从而实现适配人类偏好的效果。
受限于作者的数学水平,本节只概括性地描述偏好学习的理念,不涉及具体细节。
一个典型的 RLHF (Reinforcement Learning from Human Feedback) 流程如下:
- 收集偏好数据。一条偏好数据是形如 \(\mathrm{(input,\,output\_win,\,output\_lose)}\) 的三元组。
- 根据偏好数据训练一个模型(通常是 LLM 附加一个分类层),用于给 \(\mathrm{(input,\,output)}\) 对打分。训练时最大化打分和偏好数据的吻合程度(给 \(\mathrm{output\_win}\) 高分,给 \(\mathrm{output\_lose}\) 低分)。这个模型被称为 reward model。
- 以 reward model 为指导微调模型。这一步最大化模型输出在 reward model 上的得分,同时通过一个惩罚项避免模型偏离太远。由于 reward model 并不可微,这一步无法使用梯度下降法。通常使用强化学习领域的 PPO 算法进行优化。
PPO 过程较为繁琐,需要训练辅助模型和使用相对复杂的优化算法。DPO 通过一些数学上的调整,在保留原本算法的优秀性质的同时不再需要 reward model 和强化学习,而是直接更新模型参数。DPO 的复杂性显著低于 PPO,同时性能接近或更优。